AI 코드 에디터 Cursor가 자체 벤치마크인 CursorBench 3.1 결과를 공개했는데요. SWE-bench 같은 기존 벤치마크가 놓치는 부분, 그러니까 실제 에디터 안에서 벌어지는 지저분한 에이전트 코딩을 측정하겠다는 게 핵심이에요. 요즘 모델 발표마다 벤치마크 숫자가 쏟아져서 피로하실 텐데, 이건 방법론이 꽤 흥미로워서 뜯어볼 만합니다.
뭐가 다른 벤치마크냐면
기존 코딩 벤치마크의 문제는 문제가 너무 '깨끗하다'는 거예요. 잘 정의된 이슈, 잘 격리된 저장소, 명확한 정답. 그런데 실무는 안 그렇잖아요. CursorBench는 실제 Cursor 사용 데이터에서(익명화하고 동의받은 것만) 과제를 샘플링했어요. 여러 파일에 걸친 리팩터링, 의존성 업그레이드, 테스트 기반 버그 수정, 그리고 스펙이 애매해서 모델이 되묻거나 알아서 추론해야 하는 과제들까지요.
규모와 방식을 보면요. 12개 언어에 걸쳐 1,847개 과제(TypeScript 31%, Python 27%, Rust 9%, Go 8% 순)이고, 각 과제는 컨테이너화된 저장소 스냅샷 안에서 파일 읽기/편집, 터미널, LSP(언어 서버, 그러니까 IDE가 쓰는 코드 분석 기능) 접근까지 갖춘 완전한 에이전트 환경으로 실행돼요. 채점은 숨겨진 테스트 스위트로 하고, 400개 과제는 사람이 루브릭 기준으로 추가 검토합니다. 과제당 실제 시간 30분 제한에 Pass@1(첫 시도 성공률) 기준이에요.
3.1에서 새로 생긴 트랙 두 개가 특히 실무적인데요. 하나는 롱 호라이즌 트랙으로 도구 호출 50번 이상이 필요한 긴 과제들이고, 다른 하나는 '컨텍스트 부패(context rot)' 트랙인데 이게 뭐냐면 20만 토큰이 넘는 거대한 저장소 안에 정답에 필요한 코드가 깊숙이 묻혀 있는 상황을 시뮬레이션하는 거예요. 큰 레거시 코드베이스에서 AI 써보신 분들은 이게 왜 별도 트랙인지 바로 아실 거예요.
결과는 어떻게 나왔나
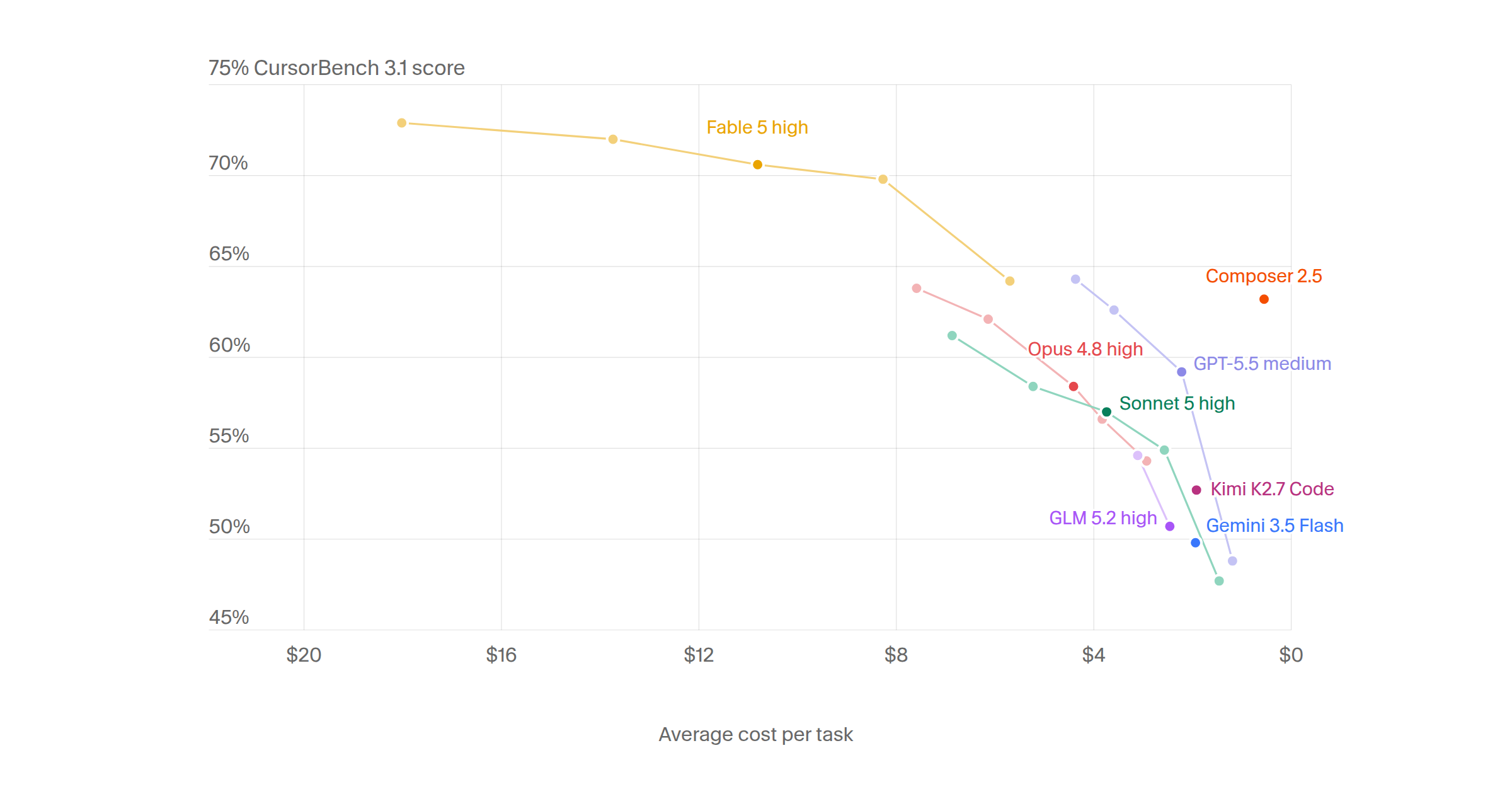
전체 Pass@1 기준으로 Claude Fable 5가 74.2%(롱 호라이즌 68.9%)로 1위, GPT-5.2-codex가 71.8%(롱 호라이즌 61.3%)로 2위였어요. 그 뒤로 Claude Opus 4.8이 69.5%, Gemini 3.1 Pro가 67.0%, Claude Sonnet 5가 66.1% 순이고요. Cursor 자체 모델인 Composer-2는 63.8%인데, 지연 시간이 4.1배 낮아서 대화형 사용의 지연-품질 파레토 프론티어에서는 제일 좋은 위치라고 해요.
숫자보다 흥미로운 건 사람이 루브릭으로 검토한 정성 평가 부분이에요. Fable 5는 스펙이 애매할 때 되묻는 비율이 52%로 2위(31%)를 크게 앞섰고, 시키지 않은 일까지 벌이는 스코프 크리프 회피에서도 1위였대요. 반면 터미널을 많이 쓰는 과제에서는 GPT-5.2-codex가 앞섰고요. 모델마다 성격이 다르다는 게 수치로 드러나는 셈이죠.
읽을 때 주의할 점
다만 짚고 갈 게 있어요. 이건 Cursor가 만든 벤치마크라는 점이에요. 자사 모델(Composer-2)이 파레토 최적이라는 결론이 나오는 평가를 자사가 설계했으니, 이해관계가 없다고 할 수는 없죠. Cursor도 이를 의식했는지 하네스, 과제 설명(비공개 저장소 내용 제외), 채점 루브릭을 전부 공개하고 평가 하네스를 오픈소스로 풀면서 다른 랩들의 정정 제출까지 받겠다고 했어요. 벤더 벤치마크치고는 투명한 편이지만, 그래도 독립 검증이 나오기 전까지는 순위 자체보다 방법론과 경향성을 보는 게 맞다고 봅니다.
우리한테 주는 시사점
실무에서 모델 고를 때 참고할 만한 관전 포인트는 이거예요. 첫째, 전체 점수와 롱 호라이즌 점수의 격차를 보세요. 격차가 큰 모델은 짧은 작업엔 강해도 긴 자율 작업을 맡기면 무너진다는 뜻이거든요. 둘째, '되묻는 능력' 같은 정성 지표가 벤치마크에 들어오기 시작했다는 것 자체가 의미 있어요. 에이전트 코딩에서는 정답률만큼이나 애매할 때 멈추고 확인하는 습관이 사고를 막아주니까요. 셋째, 지연 시간 축이 공식 지표로 등장했다는 건 '가장 똑똑한 모델'과 '에디터에서 같이 일하기 좋은 모델'이 다를 수 있다는 걸 업계가 인정하기 시작했다는 신호고요.
한 줄 정리: 코딩 AI 평가의 축이 '문제를 푸는가'에서 '실제 저장소에서, 오래, 지연 시간 안에, 눈치껏 일하는가'로 이동하고 있다. 여러분은 에이전트 코딩 도구 고를 때 뭘 제일 중요하게 보세요? 순수 성능인가요, 반응 속도인가요, 아니면 시키지 않은 일을 안 벌이는 얌전함인가요?
🔗 출처: Hacker News


"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공