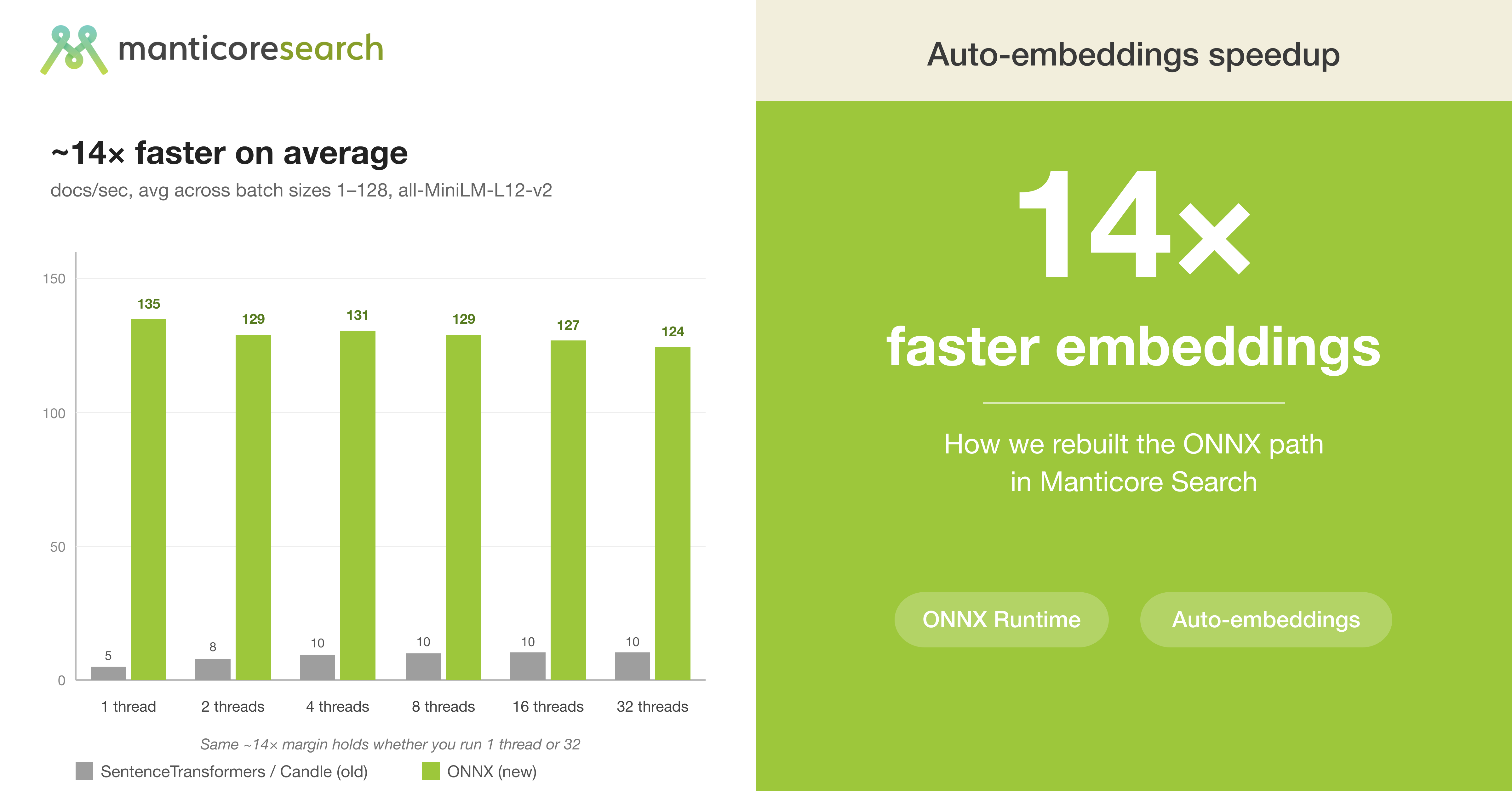
요즘 검색 기능을 만들면 키워드 검색만으로는 부족하다는 얘기를 많이 하죠. '노트북 느려요'라고 검색했을 때 '랩탑 성능 저하'라는 문서도 찾아주려면, 단어가 아니라 의미로 검색하는 시맨틱 검색이 필요한데요. 오픈소스 검색엔진 Manticore Search가 이 시맨틱 검색의 핵심 병목이던 임베딩 생성 속도를 14배 끌어올린 과정을 공개했어요. 숫자도 숫자지만, 그 과정 자체가 성능 최적화의 좋은 교과서라서 소개해요.
임베딩과 ONNX가 뭐냐면
하나씩 짚을게요. 임베딩(embedding)은 텍스트를 숫자 벡터로 바꾸는 작업이에요. '고양이'와 '냥이'처럼 의미가 비슷한 말은 벡터 공간에서도 가까운 위치에 놓이게 되죠. 이 벡터들 사이의 거리를 재면 의미가 비슷한 문서를 찾을 수 있는 거예요. 이게 시맨틱 검색의 원리고요.
그럼 ONNX는 뭐냐면, Open Neural Network Exchange의 약자로 머신러닝 모델을 담는 표준 파일 포맷이에요. 파이토치로 학습한 모델이든 뭐든 ONNX로 변환해두면, ONNX Runtime이라는 실행 엔진으로 어디서든 돌릴 수 있어요. 중요한 건 이 런타임이 C++로 되어 있어서, 파이썬 없이도 다른 프로그램 안에 임베딩 모델을 통째로 심을 수 있다는 점이에요. Manticore는 이걸 이용해서 검색엔진 안에 임베딩 생성 기능을 내장했어요. 문서를 INSERT하면 엔진이 알아서 벡터로 바꿔주는 거죠. 외부에 임베딩 서버를 따로 두거나 유료 API를 호출할 필요가 없어지는 거예요.
14배는 어디서 나왔을까
그런데 모델을 내장하는 것과 빠르게 돌리는 건 전혀 다른 문제예요. 처음 만든 경로는 동작은 했지만 느렸고, 이번에 그 경로를 바닥부터 재설계하면서 14배 차이를 만들어냈다는 건데요. 이런 종류의 최적화에서 성능이 튀어 오르는 지점은 대체로 정해져 있어요.
가장 큰 게 배칭(batching)이에요. 문서를 한 건씩 모델에 넣으면 매번 모델 실행 준비 비용을 치르게 되는데, 여러 문서를 묶어서 한 번에 넣으면 이 고정 비용이 나눠지면서 처리량이 확 올라가요. 식당에서 주문 들어올 때마다 오븐을 예열하는 것과, 주문을 모아서 한 번에 굽는 것의 차이라고 보시면 돼요. 그다음이 메모리 관리예요. 추론할 때마다 텐서(모델에 넣는 숫자 덩어리예요)를 새로 할당하고 복사하면 그 자체가 큰 오버헤드라서, 버퍼를 재사용하고 불필요한 복사를 걷어내는 것만으로도 체감이 크게 달라져요. 여기에 토크나이저(텍스트를 모델이 읽는 조각으로 자르는 부분)의 오버헤드 정리, CPU 코어를 제대로 활용하는 스레딩 구조까지 더해지면, 한 자릿수 배수의 개선이 겹치고 겹쳐서 14배 같은 숫자가 나오는 거예요.
업계 맥락: 임베딩이 DB 안으로 들어오는 흐름
이 발표가 흥미로운 건 업계 전체의 방향과 맞닿아 있어서예요. Elasticsearch는 유료 티어에서 자체 모델 추론을 내장했고, Weaviate는 벡터화 모듈을 붙일 수 있고, 반대로 pgvector나 Qdrant는 벡터 저장과 검색만 담당하고 임베딩 생성은 바깥에 맡기는 구조죠. '임베딩 생성을 어디에 둘 것인가'는 지금 검색과 벡터 DB 진영의 갈림길인데, Manticore는 오픈소스로 완전 내장 노선을 밀고 있는 거예요. 내장 방식은 파이프라인이 단순해지고 데이터가 밖으로 안 나가는 대신, 엔진의 추론 성능이 곧 전체 성능이 되니까 이번 같은 최적화가 사활이 걸린 문제가 되는 거고요.
한국 개발자에게는
실무적으로 두 가지를 생각해볼 만해요. 첫째, 임베딩 API 비용이 부담되는 팀이라면 로컬 임베딩이 충분히 현실적인 대안이 됐다는 것. CPU에서도 이 정도 처리량이 나온다면 소규모 서비스는 GPU 없이도 시맨틱 검색을 돌릴 수 있어요. 둘째, 한국어 검색 품질 문제예요. 한국어는 조사와 어미 변화 때문에 키워드 검색이 잘 깨지는 언어라서, 시맨틱 검색을 보완재로 얹으면 체감 품질이 크게 좋아지는 경우가 많거든요. 다국어 임베딩 모델을 ONNX로 변환해서 이런 엔진에 얹는 구성은 사이드 프로젝트로도 해볼 만한 크기예요.
정리하면, 임베딩 생성을 검색엔진 안에 넣되 제대로 빠르게 만들겠다는 시도가 오픈소스에서 성과를 낸 사례예요. 여러분이라면 임베딩 생성을 외부 API에 맡기시겠어요, 아니면 엔진에 내장하는 쪽을 택하시겠어요?
🔗 출처: Hacker News
"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공