데이터베이스는 어떻게 수억 건의 데이터에서 원하는 걸 순식간에 찾아낼까요?
데이터베이스를 쓰다 보면 "인덱스를 걸어라"라는 말을 귀에 딱지가 앉도록 듣게 되는데요. 그런데 정작 그 인덱스가 내부적으로 어떻게 생겼고, 왜 빠른지를 제대로 이해하고 있는 분은 생각보다 많지 않아요. 오늘은 거의 모든 관계형 데이터베이스의 인덱스 뒤에 숨어 있는 자료구조, B-Tree에 대해 이야기해보려고 해요.
PlanetScale 엔지니어링 블로그에서 이 주제를 아주 잘 정리한 글이 나왔는데요, 그 내용을 바탕으로 한국 개발자 분들이 실무에서 바로 감을 잡을 수 있도록 풀어볼게요.
B-Tree가 뭐냐면
일단 "트리"라는 자료구조는 다들 아시죠? 위에 루트 노드가 있고, 아래로 자식 노드가 뻗어 나가는 구조요. 이진 트리(Binary Tree)는 각 노드가 최대 2개의 자식을 갖는데, B-Tree는 여기서 한 발 더 나가서 각 노드가 수십~수백 개의 자식을 가질 수 있어요. 그래서 트리의 높이가 매우 낮아지거든요.
이게 왜 중요하냐면, 데이터베이스에서 데이터를 찾을 때 디스크를 읽어야 하는데요, 디스크 읽기는 메모리 접근보다 수만 배 느려요. 트리의 높이가 3이면 디스크를 3번만 읽으면 원하는 데이터를 찾을 수 있는 거예요. 수억 건의 데이터가 있어도요. 반면에 이진 트리였다면? 높이가 20~30이 넘어가니까 디스크를 그만큼 많이 읽어야 하겠죠.
쉽게 비유하자면, B-Tree는 도서관의 색인 시스템 같은 거예요. 도서관에 책이 100만 권 있다고 해도, "한국 문학 → ㄱ으로 시작하는 작가 → 김영하"처럼 2~3단계만 거치면 원하는 책을 찾을 수 있잖아요. B-Tree도 정확히 그런 원리로 동작해요.
데이터베이스 인덱스의 실제 구조
MySQL의 InnoDB 같은 스토리지 엔진에서 B-Tree 인덱스가 실제로 어떻게 저장되는지 좀 더 들어가볼게요.
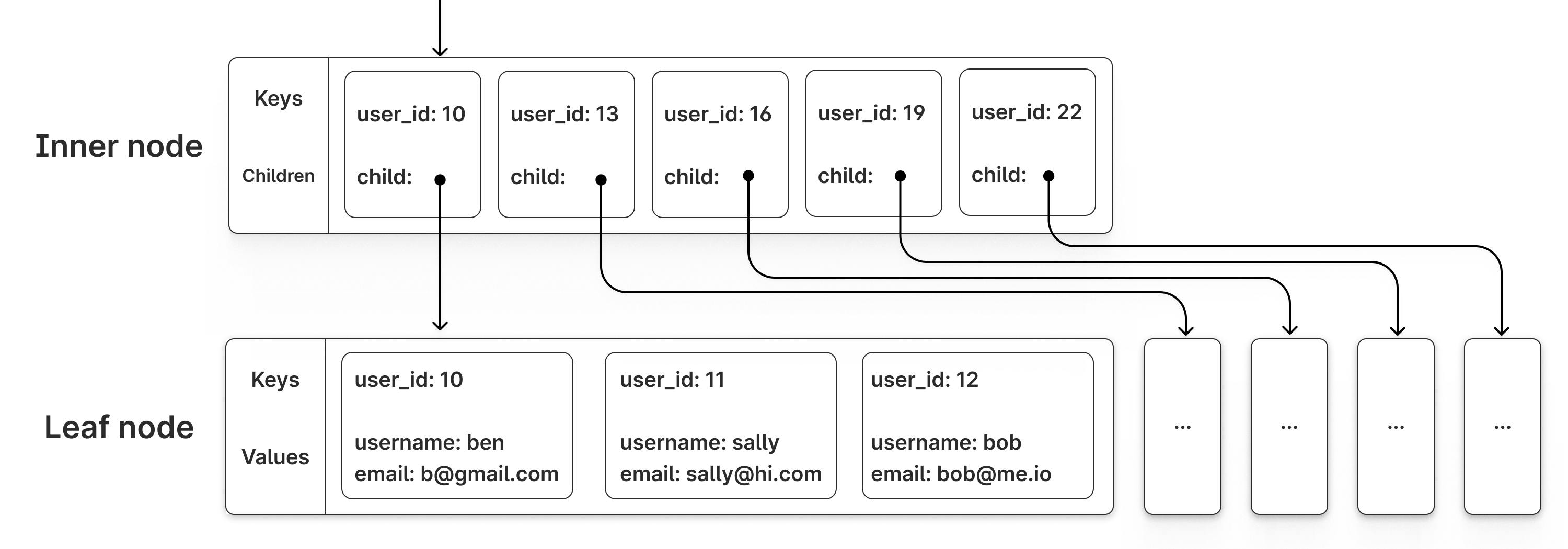
B-Tree의 각 노드는 디스크의 "페이지"에 대응돼요. 보통 페이지 크기는 16KB인데요, 이 하나의 페이지 안에 수백 개의 키-포인터 쌍이 들어갈 수 있어요. 예를 들어 정수형 인덱스라면 하나의 페이지에 키 값과 자식 페이지 포인터가 수백 개 들어가는 거죠.
리프 노드(가장 아래층 노드)에는 실제 데이터의 위치 정보가 담겨 있어요. InnoDB의 경우 프라이머리 키 인덱스(클러스터드 인덱스)에서는 리프 노드에 실제 행 데이터가 통째로 저장되고, 세컨더리 인덱스에서는 프라이머리 키 값이 저장돼요. 그래서 세컨더리 인덱스로 조회하면 먼저 세컨더리 인덱스 B-Tree를 타고 내려가서 프라이머리 키를 찾고, 다시 프라이머리 키 B-Tree를 타고 내려가서 실제 데이터를 가져오는 두 번의 트리 탐색이 일어나요.
또 하나 중요한 건, B-Tree의 리프 노드들은 서로 링크드 리스트처럼 연결되어 있다는 점이에요. 그래서 범위 검색(WHERE price BETWEEN 1000 AND 5000 같은)을 할 때 리프 노드를 옆으로 쭉 따라가기만 하면 되거든요. 이 덕분에 정렬된 순서로 데이터를 빠르게 읽어올 수 있어요.
인덱스를 걸 때 왜 컬럼 순서가 중요한지
복합 인덱스(여러 컬럼으로 만든 인덱스)를 만들 때 컬럼 순서가 왜 중요한지도 B-Tree 구조를 알면 바로 이해가 돼요. 예를 들어 (last_name, first_name) 순서로 인덱스를 만들었다고 해볼게요.
B-Tree는 먼저 last_name으로 정렬하고, 같은 last_name 안에서 first_name으로 다시 정렬해요. 전화번호부가 성(姓) 먼저 정렬하고, 같은 성 안에서 이름으로 정렬하는 것과 똑같은 원리예요. 그래서 WHERE last_name = '김'은 인덱스를 잘 타지만, WHERE first_name = '영희'만 단독으로 쓰면 인덱스를 제대로 활용할 수 없어요. 전화번호부에서 성을 모르고 이름만으로 찾으려면 처음부터 끝까지 다 뒤져야 하는 것과 같은 이치죠.
이걸 "leftmost prefix rule"이라고 하는데요, 복합 인덱스의 왼쪽부터 순서대로 사용해야 인덱스가 효과를 발휘한다는 규칙이에요. 실무에서 쿼리가 느릴 때 EXPLAIN을 찍어보면 인덱스를 안 타는 경우가 꽤 있는데, 이 규칙을 모르면 왜 안 타는지 이해하기 어렵거든요.
B-Tree vs 해시 인덱스, 뭐가 다른가요
"해시 테이블이 O(1)이니까 더 빠르지 않나요?"라는 질문을 하실 수 있어요. 맞아요, 정확히 하나의 값을 찾는 동등 비교(=)에서는 해시가 이론적으로 더 빨라요. 하지만 데이터베이스 인덱스로는 B-Tree가 압도적으로 많이 쓰이는 이유가 있어요.
해시 인덱스는 범위 검색을 할 수 없어요. WHERE age > 25 같은 쿼리는 해시로는 답이 없거든요. 정렬도 안 되고, LIKE 'abc%' 같은 접두사 검색도 못 해요. 반면 B-Tree는 데이터가 정렬되어 있으니까 이 모든 게 가능하죠. 실제 서비스에서는 동등 비교보다 범위 검색이나 정렬이 필요한 경우가 훨씬 많기 때문에 B-Tree가 "범용 인덱스"로 자리 잡은 거예요.
한국 개발자에게 주는 시사점
사실 B-Tree는 1972년에 발명된 자료구조예요. 50년이 넘었는데도 여전히 MySQL, PostgreSQL, Oracle, SQLite 등 거의 모든 주요 데이터베이스의 핵심 인덱스 구조로 쓰이고 있어요. 그만큼 근본적인 개념이라는 뜻이에요.
실무에서 당장 도움이 되는 포인트를 정리해보면, 첫째로 느린 쿼리를 만났을 때 EXPLAIN 결과를 보고 인덱스가 왜 안 타는지 이해할 수 있게 돼요. 둘째로 복합 인덱스의 컬럼 순서를 결정할 때 어떤 순서가 효율적인지 판단할 수 있고요. 셋째로 커버링 인덱스(인덱스만으로 쿼리를 처리하는 기법)가 왜 빠른지도 B-Tree 구조를 알면 자연스럽게 이해돼요.
면접에서도 단골 질문이에요. "인덱스가 내부적으로 어떻게 동작하나요?"라고 물었을 때, B-Tree의 구조와 디스크 I/O 최적화 관점에서 설명할 수 있으면 확실히 차별화가 되거든요.
마무리
B-Tree는 "디스크에서 데이터를 가능한 한 적게 읽으면서 빠르게 찾자"라는 단순하고 강력한 아이디어를 구현한 자료구조예요. 화려한 신기술은 아니지만, 데이터베이스를 쓰는 모든 개발자가 반드시 이해해야 할 기초 체력 같은 지식이에요.
여러분은 인덱스 설계할 때 어떤 기준으로 결정하시나요? B-Tree 구조를 알기 전과 후에 인덱스에 대한 이해가 달라진 경험이 있다면 공유해주세요!
🔗 출처: Hacker News


"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공