불변 데이터 구조, 느리다는 편견을 깨다
함수형 프로그래밍을 공부하다 보면 꼭 만나게 되는 개념이 있어요. 바로 불변(Immutable) 데이터 구조인데요. 데이터를 한번 만들면 절대 수정하지 않고, 변경이 필요할 때는 새로운 복사본을 만드는 방식이에요.
이 말을 처음 들으면 "그럼 배열에 원소 하나 추가할 때마다 전체를 복사한다고? 그게 어떻게 실용적이야?"라는 의문이 자연스럽게 떠올라요. 맞는 지적이에요. 순진하게 구현하면 정말 느려요. 그런데 Clojure라는 언어는 이 문제를 아주 영리한 방법으로 풀었거든요. 그게 바로 Persistent Vector예요.
Persistent가 뭔데요?
여기서 "Persistent"는 데이터베이스의 영속성(디스크에 저장)과는 다른 의미예요. 자료구조 용어로 "이전 버전이 보존된다"는 뜻이에요. 벡터에 원소를 추가해도 원래 벡터는 그대로 남아있고, 새로운 원소가 포함된 새 벡터가 반환되는 거예요. 마치 Git에서 커밋할 때 이전 커밋이 사라지지 않는 것과 비슷하다고 생각하면 돼요.
"그래서 매번 전체를 복사하는 거 아니야?"라고 물을 수 있는데, 핵심은 구조적 공유(Structural Sharing)에 있어요. 변경되지 않은 부분은 이전 버전과 새 버전이 함께 공유하고, 실제로 바뀐 부분만 새로 만드는 거예요.
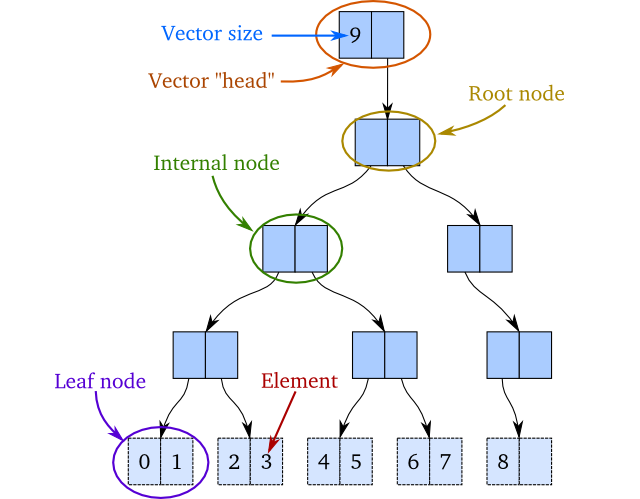
내부 구조: 32진 트라이(Trie)
Clojure의 Persistent Vector는 내부적으로 32-way branching trie라는 트리 구조를 사용해요. 트라이(Trie)가 뭐냐면, 키를 한 글자씩 쪼개서 트리의 각 레벨에 대응시키는 자료구조인데요, 여기서는 인덱스(배열의 위치 번호)를 32진법으로 쪼개서 사용해요.
구체적으로 설명해볼게요. 일반 배열에서 인덱스 1000번째 원소에 접근하려면 그냥 arr[1000]으로 바로 가죠. Persistent Vector에서는 1000이라는 숫자를 32진법으로 변환해요. 1000을 32진법으로 쓰면 [0, 31, 8]이 되는데, 이걸 트리의 루트에서부터 순서대로 따라 내려가는 거예요. 루트 노드의 0번째 자식 → 그 노드의 31번째 자식 → 그 노드의 8번째 자식, 이렇게 3단계만 거치면 원하는 원소에 도달해요.
트리의 각 노드가 최대 32개의 자식을 가질 수 있으니까, 깊이가 아주 얕아요. 32개 원소는 깊이 1, 1,024개는 깊이 2, 32,768개는 깊이 3, 약 100만 개는 깊이 4면 충분해요. 그래서 인덱스 접근의 시간 복잡도가 O(log₃₂ N)인데, 실질적으로는 거의 상수 시간이에요. 10억 개의 원소가 있어도 6단계면 되거든요.
원소를 추가하거나 수정할 때는?
원소를 수정한다고 해볼게요. 트리에서 해당 원소가 있는 경로만 새로 만들면 돼요. 루트에서 리프까지의 경로에 있는 노드들만 새로 복사하고, 나머지 노드들은 이전 버전과 공유하는 거예요. 깊이가 최대 6~7 정도니까, 노드 6~7개만 새로 만들면 되는 셈이에요. 나머지 수백만 개의 노드는 그대로 재활용하고요.
원소를 끝에 추가하는 것도 비슷해요. 마지막 리프 노드에 빈자리가 있으면 거기에 넣고 경로만 새로 만들면 되고, 리프가 꽉 차있으면 새 리프를 만들고 트리 구조를 약간 조정해요. 어느 쪽이든 작업량은 트리의 깊이에 비례하니까 매우 효율적이에요.
왜 하필 32인가?
"왜 이진 트리도 아니고 32진 트리야?"라는 궁금증이 생길 수 있어요. 이건 캐시 효율성 때문이에요. 현대 CPU는 메모리를 한 번에 캐시 라인(보통 64바이트) 단위로 읽어오는데, 노드 하나가 32개의 포인터(각 8바이트 = 총 256바이트)를 담고 있으면 캐시 활용이 꽤 좋아져요. 이진 트리처럼 노드가 잘게 쪼개져 있으면 메모리 여기저기를 뛰어다녀야 하는데, 32진 트리는 한 노드 안에서 많은 분기를 한꺼번에 처리할 수 있으니까 실제 하드웨어에서 더 빠르게 동작해요.
다른 언어에서는?
이 아이디어는 Clojure만의 것이 아니에요. Rich Hickey가 Clojure를 위해 설계한 이후로 여러 언어에 영향을 줬어요. Scala의 Vector도 같은 원리로 동작하고, JavaScript에서는 Immutable.js 라이브러리가 이 구조를 구현했어요. Rust 생태계에는 im 크레이트가 있고, Haskell에도 비슷한 구현체들이 있어요. 이 개념 자체는 Phil Bagwell이 2001년에 발표한 "Ideal Hash Trees" 논문에서 시작됐는데, Clojure가 이걸 실용적인 프로그래밍 언어에 성공적으로 적용한 대표 사례인 거예요.
최근에는 불변 데이터 구조의 중요성이 더 커지고 있어요. React의 상태 관리에서도 불변성이 핵심 원칙이고, Redux 같은 라이브러리들이 이런 개념 위에 만들어져 있잖아요. 직접 Persistent Vector를 구현할 일은 드물겠지만, 이 원리를 이해하고 있으면 왜 불변 업데이트가 생각보다 비용이 적은지 직관적으로 알 수 있어요.
한국 개발자에게 주는 시사점
프론트엔드 개발하시는 분들은 이미 불변 상태 관리를 쓰고 계실 거예요. setState에서 스프레드 연산자로 새 객체를 만드는 게 바로 이 원리의 간소화된 버전이에요. Immer 같은 라이브러리가 내부적으로 구조적 공유를 해주는 것도 같은 맥락이고요. 백엔드 쪽에서도 동시성 처리가 중요해지면서 불변 데이터 구조의 가치가 점점 올라가고 있어요. 여러 스레드가 같은 데이터를 읽어도 누가 수정할 걱정이 없으니까 락(Lock) 없이도 안전하거든요.
꼭 Clojure를 배울 필요는 없지만, Persistent Vector의 동작 원리를 이해해두면 자료구조와 알고리즘에 대한 시야가 넓어져요. 면접에서 "불변 데이터 구조가 어떻게 효율적일 수 있는지"를 설명할 수 있다면 꽤 인상적이겠죠?
정리
Clojure의 Persistent Vector는 "불변 = 느리다"는 공식을 깨주는 자료구조예요. 32진 트라이와 구조적 공유라는 두 가지 아이디어로, 거의 상수 시간에 읽기·쓰기·추가를 하면서도 이전 버전을 온전히 보존해요. 여러분은 실무에서 불변 데이터 구조를 적극적으로 활용하는 편인가요, 아니면 성능 우려 때문에 가변 구조를 선호하시나요?
🔗 출처: Hacker News


TTJ 코딩클래스 정규반
월급 외 수입,
코딩으로 만들 수 있습니다
17가지 수익 모델을 직접 실습하고, 1,300만원 상당의 자동화 도구와 소스코드를 받아가세요.
"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공