언어 모델, 새로운 방식으로 글을 쓰기 시작하다
우리가 쓰는 ChatGPT나 Claude 같은 대형 언어 모델(LLM)은 전부 자기회귀(autoregressive) 방식으로 작동해요. 이게 뭐냐면, 글자를 왼쪽에서 오른쪽으로 하나씩 순서대로 찍어내는 거예요. "오늘" 다음에 "날씨가", 그 다음에 "좋다"를 예측하는 식이죠. 마치 타자기처럼 한 글자씩 앞으로만 갈 수 있어요.
그런데 이 방식에는 근본적인 한계가 있어요. 한번 찍은 글자는 되돌릴 수 없다는 거예요. 사람이 글을 쓸 때는 전체 구조를 먼저 머릿속에 잡고, 앞뒤를 왔다 갔다 하면서 고치잖아요? 자기회귀 모델은 그게 안 되거든요. 앞에서 실수하면 뒤에서 만회할 방법이 없어요.
이런 한계를 넘어보려는 새로운 연구가 나왔어요. 바로 Introspective Diffusion Language Model이에요.
디퓨전 모델, 이미지에서 텍스트로
디퓨전(Diffusion) 모델은 원래 이미지 생성 쪽에서 대성공을 거둔 기술이에요. Stable Diffusion이나 DALL-E를 떠올리면 돼요. 작동 원리를 쉽게 설명하면 이래요. 깨끗한 이미지에 노이즈(잡음)를 조금씩 더해서 완전한 노이즈로 만든 다음, 반대로 노이즈에서 깨끗한 이미지를 복원하는 과정을 학습하는 거예요. 마치 퍼즐 조각을 흩뜨렸다가 다시 맞추는 걸 연습하는 것과 비슷하죠.
이 방식의 장점은 전체를 동시에 보면서 생성한다는 거예요. 이미지의 왼쪽 위부터 순서대로 그리는 게 아니라, 전체 캔버스를 한꺼번에 다듬어 가는 거죠. 그래서 연구자들은 생각했어요. "이걸 텍스트에도 적용하면 자기회귀의 한계를 넘을 수 있지 않을까?"
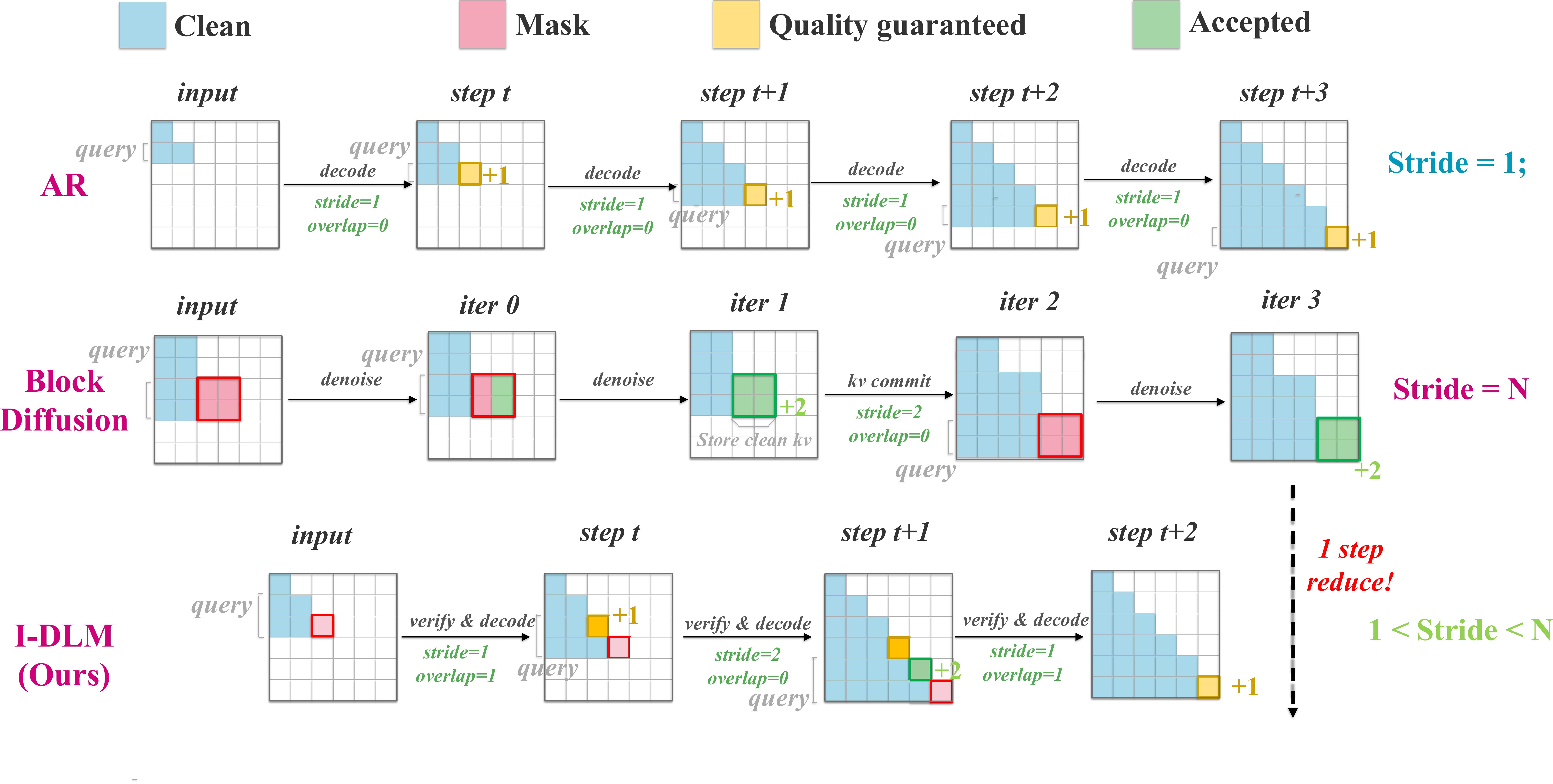
Introspective Diffusion은 바로 이 아이디어를 구현한 건데요, 여기에 한 가지 핵심적인 개선을 더했어요. 바로 자기성찰(introspection) 메커니즘이에요. 모델이 텍스트를 생성하는 과정에서 자기가 만든 중간 결과물을 다시 살펴보고, "이 부분은 좀 이상한데?" 하면서 스스로 수정하는 능력을 갖추게 한 거예요.
기존 디퓨전 언어 모델과 뭐가 다른가
사실 텍스트에 디퓨전을 적용하려는 시도는 이전에도 있었어요. 대표적으로 MDLM(Masked Diffusion Language Model)이나 SEDD 같은 연구들이 있었거든요. 그런데 기존 방식들은 큰 문제가 하나 있었어요. 자기회귀 모델에 비해 생성 품질이 확연히 떨어졌다는 거예요. 특히 긴 텍스트를 생성할 때 문맥이 꼬이거나 일관성이 무너지는 경우가 많았죠.
Introspective Diffusion은 이 문제를 해결하기 위해 모델이 디노이징(denoising, 노이즈 제거) 과정에서 자신의 이전 예측을 조건부 입력으로 다시 활용하는 구조를 도입했어요. 쉽게 말하면, 초안을 쓰고 → 초안을 다시 읽고 → 고쳐 쓰는 과정을 모델 내부에서 반복하는 거예요. 사람이 글을 퇴고하는 과정과 꽤 비슷하죠.
이 방식 덕분에 디퓨전 기반 언어 모델로서는 처음으로 자기회귀 모델에 근접하는 퍼플렉시티(perplexity) 점수를 달성했다고 해요. 퍼플렉시티는 언어 모델이 텍스트를 얼마나 잘 예측하는지를 나타내는 지표인데, 낮을수록 좋은 거예요.
왜 이게 중요한 걸까
자기회귀 모델이 이렇게 잘 되는데 디퓨전 방식을 왜 굳이 연구하느냐, 이런 의문이 들 수 있어요. 몇 가지 이유가 있어요.
첫째, 병렬 생성 가능성이에요. 자기회귀 모델은 토큰을 하나씩 순서대로 만들어야 해서 아무리 GPU가 좋아도 생성 속도에 한계가 있어요. 디퓨전 모델은 전체 시퀀스를 동시에 다루기 때문에 이론적으로 더 빠른 생성이 가능하죠.
둘째, 제어 가능성이에요. 디퓨전 모델은 이미지 쪽에서 이미 입증됐듯이 생성 과정을 세밀하게 제어하기가 상대적으로 쉬워요. 예를 들어 "이 문장의 중간 부분만 바꿔줘"라거나 "전체 톤은 유지하면서 특정 키워드를 넣어줘" 같은 편집 작업이 더 자연스러워질 수 있어요.
셋째, 추론 시간 스케일링이에요. 디퓨전 모델은 디노이징 스텝 수를 늘리면 품질이 올라가는 특성이 있어서, 중요한 작업에는 더 많은 연산을 투입하는 식의 유연한 활용이 가능해요.
한국 개발자에게 주는 시사점
당장 실무에서 쓸 수 있는 기술은 아니에요. 아직 연구 단계이고, 자기회귀 모델 대비 완전히 우위에 있다고 보기도 어려워요. 하지만 LLM의 미래 방향을 가늠해 볼 수 있는 중요한 연구라는 건 분명해요.
특히 한국에서도 네이버, 카카오, 업스테이지 등 여러 기업이 자체 언어 모델을 개발하고 있잖아요. 자기회귀 일변도에서 벗어나 디퓨전 기반의 새로운 아키텍처가 실용화된다면, 모델 개발 전략 자체가 바뀔 수 있어요. AI 엔지니어나 ML 연구자라면 이 흐름을 눈여겨볼 가치가 충분하고요, 응용 개발자라면 "앞으로 LLM API가 텍스트 편집이나 부분 재생성 같은 새로운 인터페이스를 제공할 수 있겠구나" 정도로 이해하면 좋을 것 같아요.
한줄 정리
디퓨전 언어 모델이 자기성찰 메커니즘을 통해 자기회귀 모델의 품질에 근접하기 시작했고, 이는 LLM의 근본 아키텍처가 바뀔 수 있다는 신호예요.
여러분은 자기회귀 방식의 한계를 체감해 본 적이 있나요? 디퓨전 기반 언어 모델이 실용화된다면 어떤 분야에서 가장 먼저 쓰일 거라고 생각하시나요?
🔗 출처: Hacker News


"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공