OCR이 다시 뜨거워지고 있다
OCR이라는 말 들어보셨죠? Optical Character Recognition, 즉 '이미지 속 글자를 컴퓨터가 읽어내는 기술'이에요. 스캔한 문서나 사진 속 글자를 텍스트로 바꿔주는 거죠. 오래된 기술 같지만, 요즘 AI 시대에 다시 엄청 중요해졌어요. 왜냐면 LLM(대형 언어모델)에게 회사 문서, 논문, 계약서, 영수증 같은 자료를 먹이려면 일단 그 안의 글자와 표를 정확하게 뽑아내야 하거든요. OCR이 부정확하면 그 위에 쌓는 AI도 다 엉망이 돼요. 바이두(Baidu)가 공개한 Unlimited OCR는 바로 이 OCR을 한 단계 끌어올린 프로젝트예요.
기존 OCR의 한계: 긴 문서를 잘게 잘라야 했다
기존 방식이 어떻게 동작했는지 먼저 볼게요. 보통 OCR은 여러 단계를 거쳐요. 먼저 이미지에서 글자가 어디 있는지 찾고(검출), 그 부분을 읽고(인식), 표나 단락 같은 레이아웃을 분석하죠. 그런데 문서가 길어지면 문제가 생겨요. 수십, 수백 페이지짜리 PDF를 한꺼번에 처리하기는 어려우니까 작은 조각으로 잘라서(chunking) 따로따로 처리한 다음 다시 이어붙여야 했어요.
이게 왜 문제냐면요, 표 하나가 두 페이지에 걸쳐 있거나, 앞 페이지의 제목이 뒤 페이지 내용을 설명하는 경우처럼 문맥이 페이지를 넘나들 때 그 연결이 뚝 끊겨버려요. 조각조각 처리하면 전체 문서의 구조와 흐름을 놓치는 거죠. 게다가 이어붙이는 과정에서 순서가 꼬이거나 내용이 중복되고 누락되기도 하고요.
Unlimited OCR의 핵심: 한 번에, 끝까지
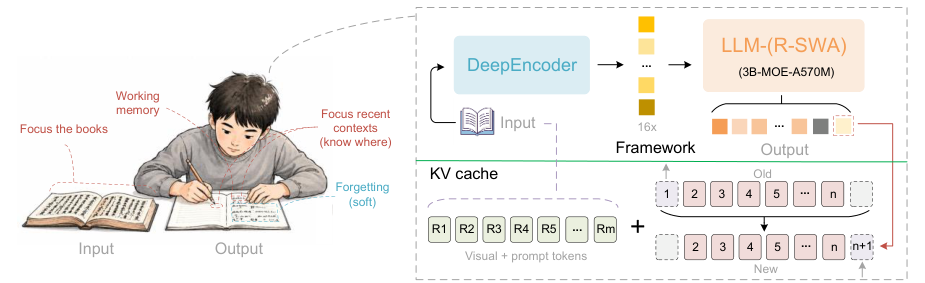
Unlimited OCR가 내세우는 건 '원샷 롱호라이즌 파싱(one-shot long-horizon parsing)'이에요. 풀어서 말하면 '아주 긴 문서를 자르지 않고 한 번에 끝까지 읽어낸다'는 뜻이에요. 잘게 쪼개지 않으니 페이지를 넘나드는 표나 문맥도 자연스럽게 이어지고, 문서 전체를 하나의 흐름으로 이해할 수 있어요.
이게 가능해진 배경에는 비전-언어 모델(VLM, Vision-Language Model)의 발전이 있어요. 이게 뭐냐면, 이미지를 '보고' 동시에 텍스트를 '이해하고 생성하는' AI예요. 예전엔 글자 검출, 인식, 레이아웃 분석을 따로 만든 모듈로 처리했다면, 이제는 하나의 모델이 문서 이미지를 통째로 보고 곧장 구조화된 텍스트(마크다운이나 표 형태)로 뽑아내요. 단계가 단순해지고, 모델이 문서 전체 맥락을 한눈에 보니까 정확도와 일관성이 함께 올라가는 거죠.
업계 맥락
문서를 통째로 읽어내는 VLM 기반 OCR은 지금 가장 경쟁이 치열한 분야 중 하나예요. 논문에 특화된 Nougat, 오픈소스 Marker, GOT-OCR2.0, 그리고 Mistral OCR, 알렌AI의 olmOCR 같은 프로젝트들이 줄줄이 나오고 있죠. 다들 '문서를 LLM이 바로 먹을 수 있는 깨끗한 텍스트로 바꾸자'는 비슷한 목표를 향해 달리고 있어요. 그중에서 Unlimited OCR는 특히 '긴 문서를 끊지 않고 통째로 처리하는 능력'을 차별점으로 내세운 거예요. 문서 길이의 한계를 깬다는 점에서 이름 그대로 'Unlimited(무제한)'인 셈이죠.
한국 개발자에게 주는 시사점
요즘 많은 분들이 사내 문서로 RAG(검색 증강 생성, AI가 우리 회사 자료를 참고해서 답하게 하는 기법)를 만들고 있잖아요. 이때 가장 골치 아픈 게 바로 PDF 안의 표와 복잡한 레이아웃을 깨끗하게 뽑아내는 거예요. 긴 문서를 잘라서 처리하다 보면 표가 깨지고 문맥이 끊기는 문제를 다들 한 번쯤 겪어봤을 거예요. 이런 '긴 문서 통째 처리' 기술은 한국어 문서에도 적용 가치가 충분해요. 다만 한국어·한자 혼용 문서나 관공서 양식처럼 우리 환경 특유의 자료에서 얼마나 잘 되는지는 직접 테스트해봐야 하고요. 오픈소스로 공개됐으니 직접 돌려보면서 한국어 성능을 가늠해보는 것도 좋은 실험이 될 거예요.
OCR은 이제 단순히 글자를 읽는 걸 넘어 '문서를 통째로 이해하는' 방향으로 가고 있어요. 여러분은 어떤 문서를 AI에게 읽히고 싶으세요? 긴 문서를 다루며 겪은 OCR 고생담이 있다면 댓글로 나눠주세요.
🔗 출처: Hacker News


"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공