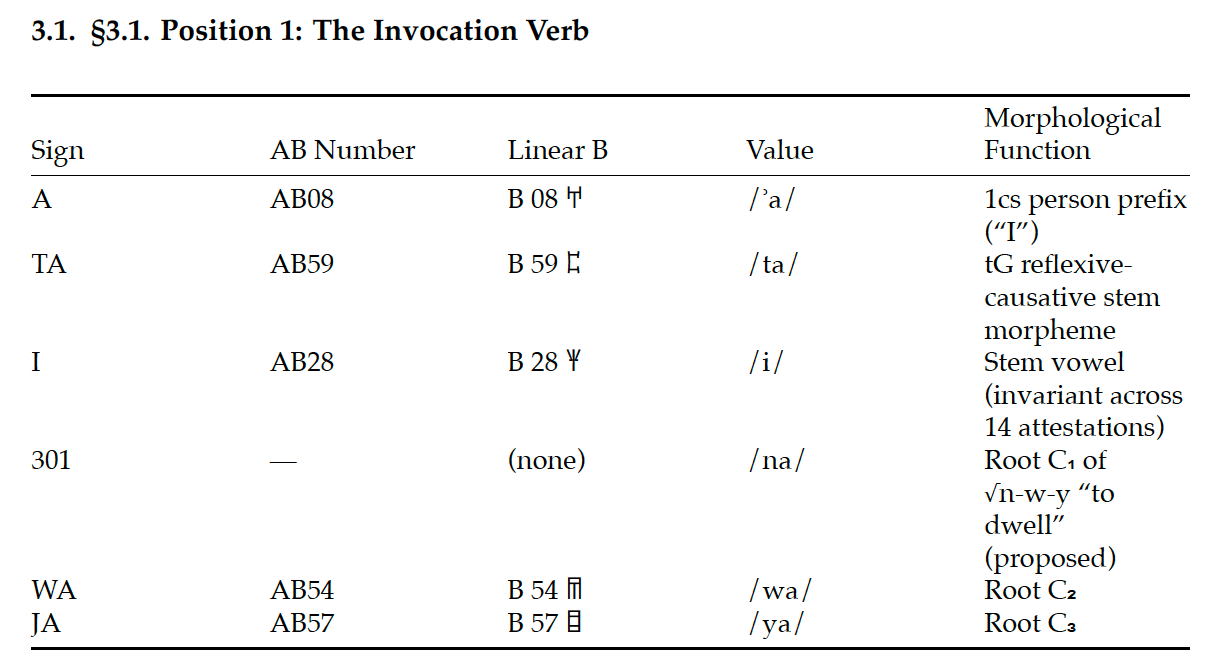
'아무도 못 읽는 문자'를 풀었다는 주장
고대 문자 중에는 아직도 인류가 읽지 못하는 것들이 있어요. 그중 유명한 게 '선형문자 A(Linear A)'예요. 기원전 1800~1450년경 크레타섬의 미노아 문명이 쓰던 문자인데, 점토판에 새겨진 기록은 잔뜩 남았지만 아무도 그 내용을 해독하지 못했어요. 그런데 한 아마추어 연구자가 이걸 풀었다고 주장하는 글이 나왔어요. 결론부터 말하면, 이런 주장은 흥미롭게 보되 아주 신중하게 걸러서 읽어야 해요. 왜 그런지 차근차근 풀어볼게요.
선형문자 A가 왜 그렇게 어려운가
여기서 헷갈리기 쉬운 게 '선형문자 B'예요. 이름이 비슷한 B는 1952년 마이클 벤트리스라는 영국의 아마추어 천재가 해독에 성공했고, 알고 보니 아주 오래된 형태의 그리스어였어요. 사람들은 '그럼 A도 곧 풀리겠네?'라고 기대했지만, 70년이 지나도록 미궁이에요.
이유가 있어요. B가 풀린 건 그 바탕 언어(그리스어)가 우리가 이미 아는 언어였기 때문이에요. 소리값을 맞춰보니 아는 단어가 튀어나온 거죠. 그런데 A는 사정이 달라요. B가 A에서 기호를 많이 빌려왔기 때문에 '이 글자는 대략 이런 소리일 것이다'까지는 추정할 수 있어요. 문제는 정작 그 소리로 단어를 읽어봐도, 그게 어떤 언어인지를 모른다는 거예요. 미노아어는 그리스어도 아니고, 현재까지 알려진 어떤 언어와도 뚜렷한 친척 관계가 확인되지 않았거든요. 비교할 사전이 없는 셈이죠. 게다가 남아 있는 자료도 대부분 '양 100마리, 기름 몇 단지' 같은 짧은 행정·회계 기록이라 문맥이 빈약해요. 비유하자면, 알파벳 발음은 어렴풋이 아는데 그게 어느 나라 말인지 모르고, 게다가 읽을 수 있는 건 영수증 쪼가리뿐인 상황이에요.
'풀었다'고 인정받으려면
그래서 진짜 해독으로 인정받는 건 엄청나게 까다로워요. 단순히 '이 단어는 이런 뜻일 것 같다'는 그럴듯한 해석 몇 개로는 부족해요. 같은 규칙을 전체 자료에 일관되게 적용했을 때 모순 없이 읽혀야 하고, 새 점토판이 나와도 그 규칙으로 읽혀야 하며, 무엇보다 다른 학자들이 검증(peer review)하고 재현할 수 있어야 해요. 아마추어 해독 주장이 매번 무너지는 지점이 바로 이 '일관성'과 '검증'이에요. 몇 단어는 그럴듯하지만 전체로 확장하면 앞뒤가 안 맞는 경우가 대부분이거든요.
AI 시대, 더 조심해야 하는 이유
요즘은 여기에 AI라는 변수가 끼어들었어요. 실제로 컴퓨터로 고대 문자를 다루는 진지한 연구가 있어요. 딥마인드의 'Ithaca'는 손상된 고대 그리스 비문을 복원하고 연대를 추정하는 모델이고, MIT 등에서는 선형문자 B나 우가리트어 같은 문자를 머신러닝으로 해독하는 실험도 했어요. 다만 이런 연구들은 '이미 답을 아는 문자'로 방법을 먼저 검증한 뒤 조심스럽게 확장해요.
문제는 요즘 누구나 쓰는 거대 언어모델(LLM)이에요. LLM은 그럴듯한 패턴을 만들어내는 데 천재적이라서, '선형문자 A를 해독해줘'라고 하면 아주 자신만만하고 매끈한 '해독 결과'를 술술 뱉어내요. 그런데 그게 맞다는 보장은 전혀 없어요. 오히려 없는 걸 지어내는(환각, hallucination) 경향이 있죠. 즉, AI는 '그럴듯하지만 틀린 해독'을 그 어느 때보다 쉽고 대량으로 만들 수 있게 됐어요. 해독 주장이 갑자기 늘어난다면, 이 점을 의심해봐야 해요.
한국 개발자에게
이건 고고학 얘기로만 끝나지 않아요. AI가 내놓는 결과를 어떻게 받아들여야 하는가에 대한 좋은 훈련이거든요. 핵심은 '검증 가능성'과 '재현성'이에요. AI가 어떤 답을 매끄럽게 내놨을 때, '이게 전체 데이터에 일관되게 들어맞나? 다른 사람이 같은 방법으로 재현할 수 있나? 반증할 방법이 있나?'를 물어야 해요. 자신감 있는 말투는 정답의 근거가 전혀 아니고요.
기술적으로도 닿는 지점이 많아요. 자료가 적은 언어(저자원 언어)나 죽은 언어를 다루는 NLP, 옛 문서를 읽는 OCR, 한자 고문서나 이두·구결처럼 우리 고문헌을 디지털화하고 해석하는 작업까지 같은 고민을 공유해요. 데이터가 부족할수록 모델은 자신 있게 헛소리를 하기 쉽고, 그래서 사람의 검증이 더 중요해진다는 교훈이죠.
마무리
선형문자 A가 언젠가 풀린다면 그건 멋진 일이에요. 하지만 '풀었다'는 주장과 '실제로 풀린 것'은 전혀 다른 얘기고, AI 시대에는 그 둘을 구분하는 눈이 더더욱 필요해요. 여러분은 AI가 자신만만하게 내놓은 결과를, 어떤 기준으로 '믿을 만하다/아니다'를 판단하세요?
🔗 출처: Hacker News

"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공